Citadel AI、大規模言語モデルの信頼性向上ツール「LangCheck」をOSSで公開

「信頼できるAI」を社会実装するCitadel AIは12日、企業や公的機関・教育現場等で導入検討が進んでいる、大規模言語モデルを用いた業務アプリケーションについて、その信頼性を向上するツール「LangCheck(ラングチェック)」を、GitHub上でオープンソースとしてした。
LangCheckを開発や運用に組み込むことで、大規模言語モデルを、より安心・安全な環境で利用できるようになるという。日本語にも対応している。
なおLangCheckの公開に合わせ、大規模言語モデルとそのアプリケーションの開発・運用に関わる課題と対策をまとめたブログ記事も、同社ホームページで連載開始。同社が社内ハッカソンを通じて学んだ実体験も交えて記載している。
Open AIやGoogle等から公開されている大規模言語モデル(Large Language Model:LLM)の技術進歩には目覚ましいものがあり、社会環境や仕事環境を大きく一変させる可能性を秘めている。
一方で、現状のLLMの多くは、インターネット上の情報を元に、その基本となる学習を行っているため、間違った情報や適切でない情報を学習してしまっているケースや、特定の専門領域や言語については未学習領域が残っており、誤った出力をしてしまうケースも散見される。
こうしたLLMを、自らの業務用アプリケーションに組み込んで活用する場合、そのアウトプットの品質によっては、適切な企業活動に支障を来たしたり、企業ブランドやコンプライアンスにも大きな影響を及ぼすリスクが生じる。
LLMの開発・運用に関わる社内のガバナンス体制を整えることに加え、具体的な技術的検証・技術監視体制を整えることは非常に重要。
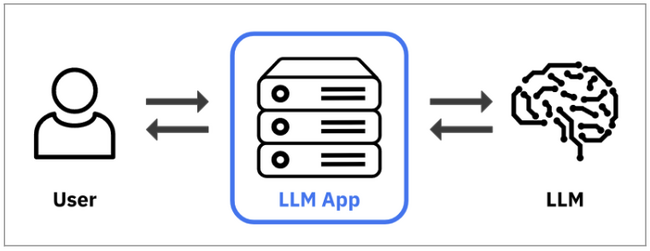
LLMを実際に企業が利用しようとする場合、GPT-3.5(ChatGPTのベースとなるモデル)のような基盤モデル(Foundation Model)を、自ら開発し学習させるようなことは現実的には限られ、多くのケースでは以下の図のように、既存のLLMを業務用途向けに活用するためのアプリケーション(LLM App)を開発し、LLM Appを通じて利用するケースが多いと考えられる。
こうした場合、基盤モデルである第三者のLLM自体の品質や信頼性を、企業側で直接的に制御したり改善することは難しく、企業のLLM App側で、以下2点の対策を取ることが非常に重要なポイントになる。
①LLM Appの品質・性能向上に向けた「攻めの取り組み」
②LLM Appの問題のある振る舞いを検証し抑制する「守りの取り組み」
LLMの場合、入出力形態が定型的でなく、従来のAIシステム評価で利用してきたようなベンチマークでは、精度や品質を測ることが困難。そのためには、LLM特有の技術的な品質評価方法が必要になる。さらに、一般公開されているLLMのテストツールは存在しても、どれを採用すべきかの判断が難しく、インターフェースも統一されておらず、作業時間もかかり、特定の言語にしか対応していないなど、多くの問題を抱えている。
 こうした課題を解決し、より確信を持って、高品質な業務用のLLM Appを開発・運用できる環境を、エンジニアや企業の皆様と共に早期に実現したい、それが今回同社が「LangCheck(ラングチェック)」をGitHub上でオープンソースソフトウェア(OSS)として公開する目的だという。
こうした課題を解決し、より確信を持って、高品質な業務用のLLM Appを開発・運用できる環境を、エンジニアや企業の皆様と共に早期に実現したい、それが今回同社が「LangCheck(ラングチェック)」をGitHub上でオープンソースソフトウェア(OSS)として公開する目的だという。
LangCheckは、多様なLLMテストツールを網羅的にパッケージ化して備えている。統一化されたインターフェースで、簡便にLLM Appの検証を行い、品質を改善したり、運用時の異常をモニタリングすることに役立てることができる。また、すべての機能について、日本語と英語を手始めに、多言語対応を拡充していく計画。以下はLangCheckに含まれる機能の一例。
・お客様のデータセットに基づく正解テキストとの一致判定
・事実との一致度合いを測るFactual Consistencyチェック
・入出力のスキーマチェック
・有害な出力や差別的な出力を調べるToxicityチェック
・文法・単語等の誤りを調べるFluencyチェック
・ジティブ・ネガティブ表現に関わるSentimentチェック等
関連URL
関連記事





注目記事
-

2026-3-11
日本経営協会、生成AIの業務活用2位は「文章校正」1位は?
日本経営協会は、2025年9月10日~9月18日の期間、企業・団体に勤務するビジネスパーソン729名… -

2026-3-11
アイスマイリー、物流・交通・運輸向けAIサービスカオスマップ公開
AIポータルメディア「AIsmiley」を運営するアイスマイリーは10日、現場の課題に応じた最適解を… -

2024-9-19
小学校の授業における生成AIの活用と文科省ガイドライン
小学校の授業における生成AIの活用は、教育の質を向上させる新たな可能性を秘めている。生成AIを活用す… -

2024-8-19
生成AIの種類(ChatGPT, Gemini, Copilot)・特徴と使い方
生成AI(生成型人工知能)は、テキスト、画像、音声などのコンテンツを自動で生成する技術。日本国内でも… -

2023-8-21
総社市スマホ市役所、生成AIを用いた対話応答型サービスを開始
岡山県総社市とBot Expressは18日、7月に開設した総社市スマホ市役所で、生成AIを用いた対…