
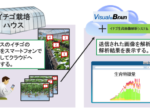
富士通研究所は16日、超高圧縮した映像からでも高精度に映像の内容を認識できる映像圧縮技術を開発したと発表した。
近年、ディープラーニングによる画像認識の飛躍的な性能向上により、映像から情報を抽出する画像認識AIソリューションが注目され、AI認識に特化した映像圧縮技術の開発が活発化している。特に、監視・確認作業などをAIによって自動化する場合には画像を復元せずに、AIが画像認識するために必要な深層特徴量のみを圧縮・伝送する技術が注目されている。
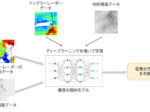
今回、同社独自開発の高次元データ解析技術「DeepTwin(ディープツイン)」を深層特徴量の圧縮に応用し、画像認識精度を低下させることなく、従来のH.265による映像圧縮とAIを組み合わせた一般的な方式と比較して、100倍以上の圧縮率を達成可能な映像圧縮技術を開発した。
今回開発した技術を用いることで、AIによる画像認識性能の劣化を一定に抑えながら、従来方式を大きく超える高圧縮を行うことができる。具体的には、AI認識モデルの一種であるVGG16を用い、映像に映っている物体を汎用的な用途として100カテゴリに分類するタスクに対して本技術を適用した場合、非圧縮の認識率から5%劣化するときの、H.265を用いた画像ベースの方法と比較して、100倍の圧縮性能を達成できた。また、例えば自動車やトラック、オートバイといった車両の分類など特定用途を想定して20カテゴリに分類する場合には、300倍の圧縮性能となり、いずれの認識劣化量の場合においてもH.265ベースの方式と比較して高い圧縮性能を達成できたという。
本技術の活用により、画像認識AIソリューションの普及に伴ってますます大容量化する映像伝送データ量の増加を抑制するとともに、限りある通信資源の効率的な利用を実現し、より持続可能な世界の実現に貢献するとしている。
関連URL
関連記事


注目記事
-

2026-3-11
日本経営協会、生成AIの業務活用2位は「文章校正」1位は?
日本経営協会は、2025年9月10日~9月18日の期間、企業・団体に勤務するビジネスパーソン729名… -

2026-3-11
アイスマイリー、物流・交通・運輸向けAIサービスカオスマップ公開
AIポータルメディア「AIsmiley」を運営するアイスマイリーは10日、現場の課題に応じた最適解を… -
2025-3-15
企業の45%が生成AIを利用、日常業務では80%超の企業が利用成果を認識 =JIPDECとITR調べ=
日本情報経済社会推進協会(JIPDEC)とアイ・ティ・アール(ITR)は14日、国内企業1110社の… -

2025-3-5
BizTech、『今さら聞けない!ChatGPT基本のキ』ホワイトペーパー公開
最適なAI開発会社やAIサービスの選定を支援するコンシェルジュサービス「AI Market」を運営す… -
2025-2-18
アイスマイリー、「AIエージェントカオスマップ 2025」を公開
AIポータルメディア「AIsmiley」を運営するアイスマイリーは17日、「AIエージェントカオスマ…