楽天、日本語に最適化した新たなAIモデルを発表
- 2024/12/20
- ものづくり
- LLM, SLM, オープンソースコミュニティ, 小規模言語モデル, 日本語, 日本語大規模言語モデル
楽天グループ(楽天)は18日、Mixture of Experts(MoE)(*1)アーキテクチャを採用した新しい日本語大規模言語モデル(LLM)「Rakuten AI 2.0」と、楽天初の小規模言語モデル(SLM)「Rakuten AI 2.0 mini」の2つのAIモデルを発表した。両モデルは、AIアプリケーションを開発する企業や技術者などの専門家を支援することを目指しており、来春を目途にオープンソースコミュニティに向けて公開予定。
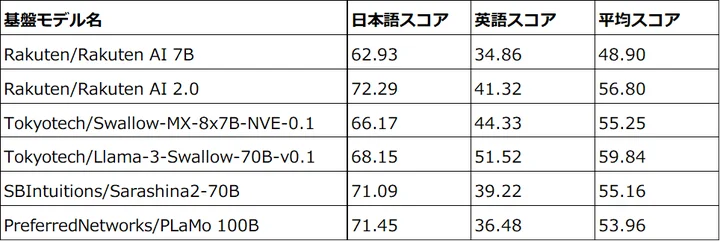
「Rakuten AI 2.0」は、2024年3月に公開した日本語に最適化した高性能なLLMの基盤モデル「Rakuten AI 7B」を基に開発した8x7BのMoE基盤モデル(*2)。本LLMは、8つの70億パラメータで構築した「エキスパート」と呼ばれるサブモデルで構成されている。トークンはルーターによって選定された最も適した2つの「エキスパート」に処理される。それぞれの「エキスパート」とルーターは共に高品質な日本語と英語の言語データを用いた継続的な学習を行っている。
楽天が初めて開発したSLM「Rakuten AI 2.0 mini」は、15億パラメータの基盤モデル。本SLMは、内製の多段階データフィルタリング、アノテーションプロセスを通じてキュレーションおよびクリーンアップされた広範な日本語と英語のデータセットで最初から学習されており、テキスト生成において高性能かつ高精度な処理を実現している。
「Rakuten AI 2.0」は、入力トークンに対して最も関連性の高い「エキスパート」を動的に選択する高度なMoEアーキテクチャを採用しており、計算効率と性能を最適化する。本LLMは、8倍規模の高密度モデルに匹敵する性能を発揮するが、消費計算量においては1/4程度に抑えることができる。
(*1)Mixture of Expertsアーキテクチャは、モデルが複数のサブモデル(エキスパート)に分割されているAIモデルアーキテクチャ。推論および学習中は、最も適したエキスパートのサブセットのみがアクティブ化され、入力処理に使用されることで、より汎用的で高度な推論を行うことができる。
(*2)基盤モデルは、大量のデータで事前学習され、その後特定のタスクやアプリケーションに微調整できるモデル。
関連URL
関連記事




注目記事
-

2026-3-11
日本経営協会、生成AIの業務活用2位は「文章校正」1位は?
日本経営協会は、2025年9月10日~9月18日の期間、企業・団体に勤務するビジネスパーソン729名… -

2026-3-11
アイスマイリー、物流・交通・運輸向けAIサービスカオスマップ公開
AIポータルメディア「AIsmiley」を運営するアイスマイリーは10日、現場の課題に応じた最適解を… -

2024-9-19
小学校の授業における生成AIの活用と文科省ガイドライン
小学校の授業における生成AIの活用は、教育の質を向上させる新たな可能性を秘めている。生成AIを活用す… -

2024-8-19
生成AIの種類(ChatGPT, Gemini, Copilot)・特徴と使い方
生成AI(生成型人工知能)は、テキスト、画像、音声などのコンテンツを自動で生成する技術。日本国内でも… -

2023-8-21
総社市スマホ市役所、生成AIを用いた対話応答型サービスを開始
岡山県総社市とBot Expressは18日、7月に開設した総社市スマホ市役所で、生成AIを用いた対…